
Background: I’m Kyle, the founder of OpenPipe. OpenPipe is a managed fine-tuning service that makes it easy to build your own LLMs that achieve very high accuracy on a specific task. In this post we’ll go under the covers and explain RLHF, which is one of the techniques we use to accomplish this.
What do the following Hacker News stories have in common?
None reached the front page; in fact none of them even got any upvotes! But they were all identified by a fine-tuned model as being likely to do well on HN. And subjectively (as someone who spends far more time on HN than I should) I actually agree with the model on this one; those all look like stories that deserved more attention than they got.
In this post we’ll discuss how to build a reward model that can predict the upvote count that a specific HN story will get. And in follow-up posts in this series, we’ll use that reward model along with reinforcement learning to create a model that can write high-value HN stories!
RL and RLHF: A 2-Minute Intro
Reinforcement learning (RL) is a set of ML techniques that improves a model’s performance by letting it take actions in an environment, and then get rewarded or penalized for those actions. Based on the rewards or penalties, the model’s behavior is updated over time to (hopefully) do more of the actions that are rewarded, and avoid those that are penalized.
Reinforcement learning from human feedback (RLHF) was developed by OpenAI and first described here as a way of adapting RL techniques to LLMs specifically. The first key step is to develop a reward model, which is a model that takes an input and output from an LLM, and tries to predict how “good” the output is. The “human feedback” part of RLHF refers to using humans to rate or compare outputs, and using that human preference data to train reward models. However, there are often other signals you can use to determine an output’s quality and train your model, as we’ll see.
Once you have a reward model, the second step is to use it to improve the performance of your generation model, by training your model to create outputs that have a higher reward on average. There are lots of techniques possible here depending on your domain and the tools you have available—we’ll cover these in the next post!
Whence Data?
To train a good reward model, the most critical input is high-quality feedback data. This can take many forms. At OpenPipe we have some customers building “co-pilot” or autocomplete flows, where the model suggests an action that the user can accept or reject. In this case, tracking whether an output was accepted or rejected is a great signal. For certain applications like chatbots or recommendation systems, you can proactively offer the user several potential outputs to choose from, and use which option they preferred as your feedback signal.
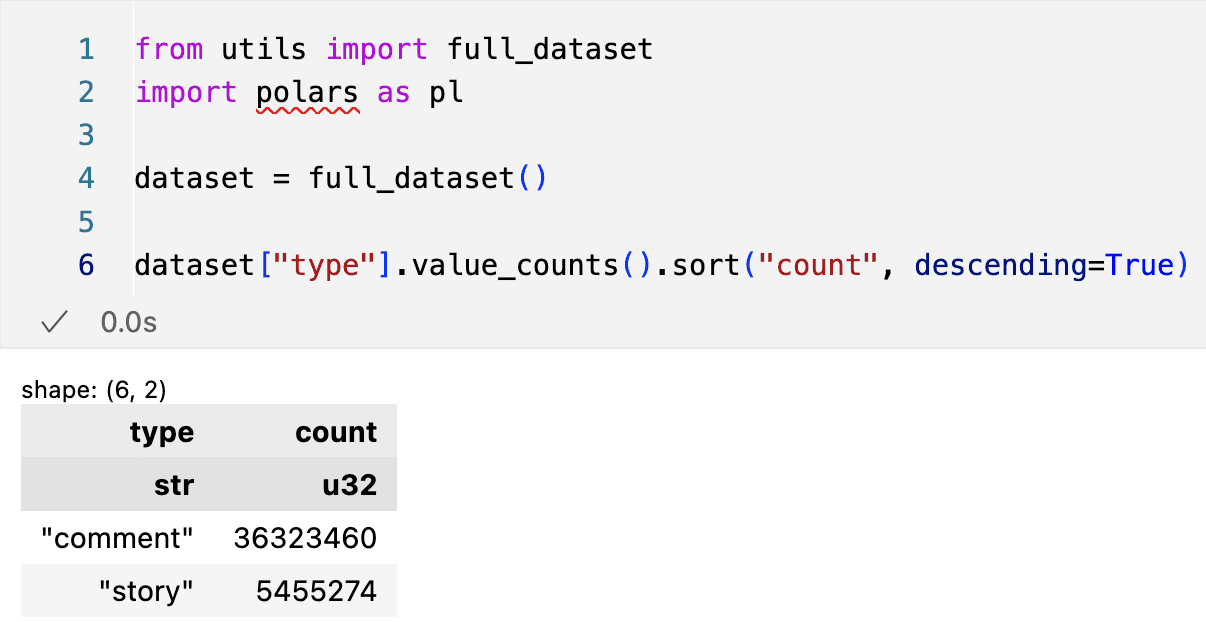
In our case we’ll go with a readily available dataset: HN stories along with their upvote counts. Upvote counts are a great reward signal; while they’re somewhat noisy, upvote count is usually correlated with post quality. For convenience in this project, I’ve scraped every HN post and comment ever (all 41 million of them!) and uploaded the full set here. Using Polars, let’s take a quick look at how many posts and comments we have(1):
Defining the Task
Ok, we have 5 million stories, that’s plenty to train a model! But we also have a problem. Our dataset has the story title, URL, date and submitter, but for most of the stories it doesn’t have the content, because it’s just an off-platform link. This might cause trouble for our reward model; a story’s content is often very important to whether users choose to upvote it or not. Without that information the reward model might not be able to make a good prediction!
One option would be to scrape the URLs for those 5 million posts (and hope they still exist). But to simplify, instead I’ll just limit to stories that have only text bodies, instead of links. That leaves us with ~150K stories to deal with.

Nice, that should be manageable! Let’s take a look at how those are distributed chronologically:
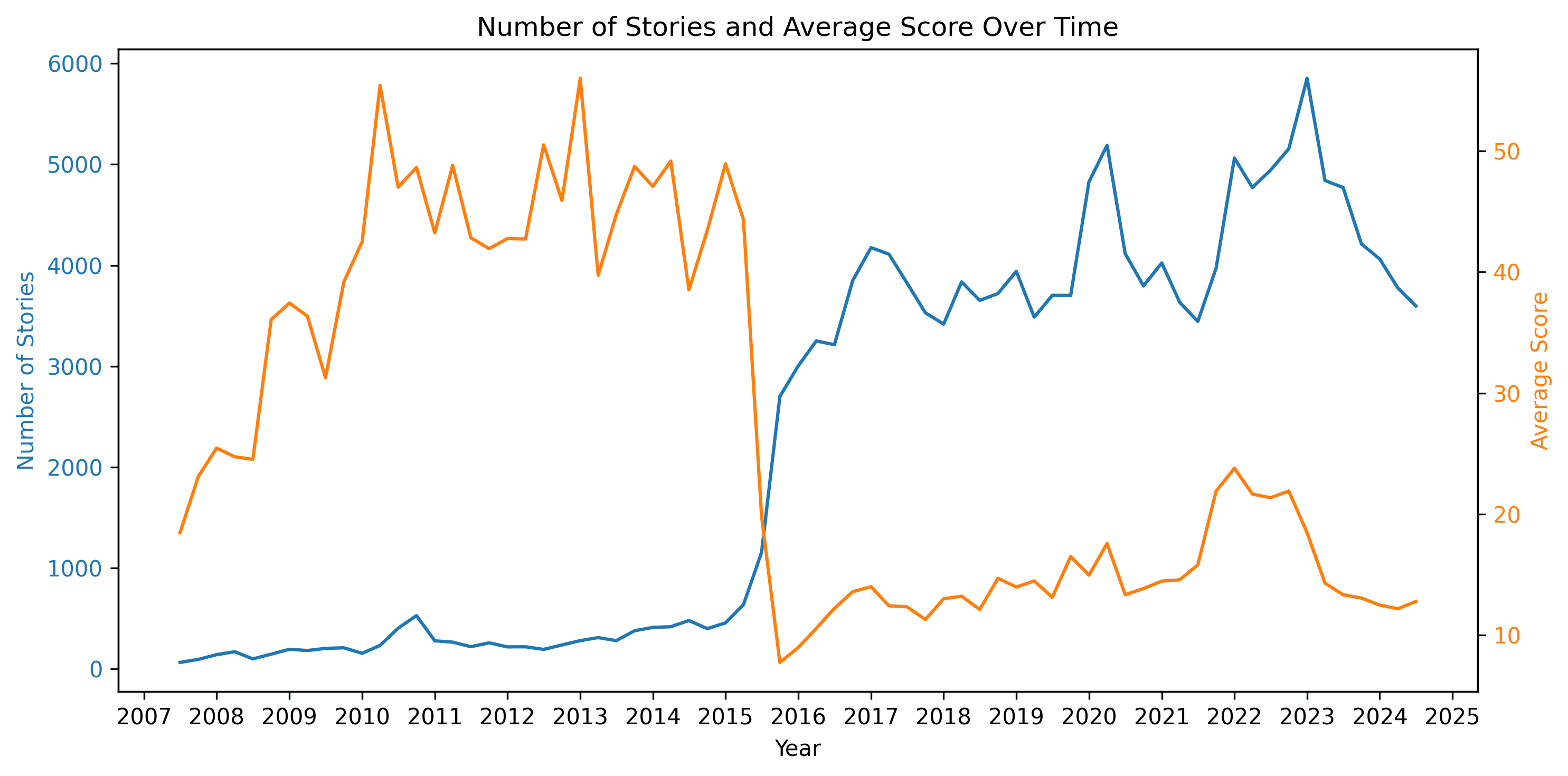
Woah, the graph looks remarkably flat… as long as you focus on the 2008-2015 period, or 2016-2024 period. But in 2015 there is a stark discontinuity, where the number of stories (with text) shoots up by >10x, and the average score drops by 5x! Is this some kind of eternal September?
To avoid potential data drift issues from that discontinuity, we’ll limit our dataset to the post-2016 stories. That way the model we create will be more attuned to what makes an HN story good or bad today, which will be helpful for future posts in the series.
Next, let’s quickly plot the distribution of story scores. For the rest of this exercise we’ll actually use the natural log of post score as the number we’re tracking, instead of the raw score itself. This smooths out the distribution a bit, which will hopefully make life easier for our model. Effectively, this transformation means that its task will be to predict the “order of magnitude” of a score rather than the score directly. This intuitively maps more closely to what we want, which is a prediction of the “order of magnitude” of a post’s score. A model that can tell us whether a story should get popular at all is more tractable than one that tries to guess whether it will get 120 vs 200 upvotes (a harder task).

Training the Model
Actually training the model is easy and fun! You can find the full code I used here. A few things to call out:
-
Since this isn’t a generative task (we’re just trying to predict a single score, not a string of text) our model architecture options are wide open! We could use classic encoder models like RoBERTa or DeBERTaV3, which are often used for this kind of problem. However, in practice I’ve found that modern LLMs that do well on generative tasks are also extremely strong on this kind of predictive task, so I’ve used Llama 3.1 8B here(2).
-
It’s super important that your training inputs includes all the information your model will need to make predictions. In this case, I included the post title, author, date, and content. All of those factors could be relevant to the chance a story gets voted up.
-
I used the Liger Kernel optimizations for both training and later inference. This sped up training time by ~30% and cut RAM usage significantly while maintaining model quality.
Training on 114K stories for one epoch on an H100 on Runpod took about 1.5 hours and cost $4.05. That’s not much time for a model that (hopefully) understands all of HN!
We can also follow along the performance on our validation set as training happens:
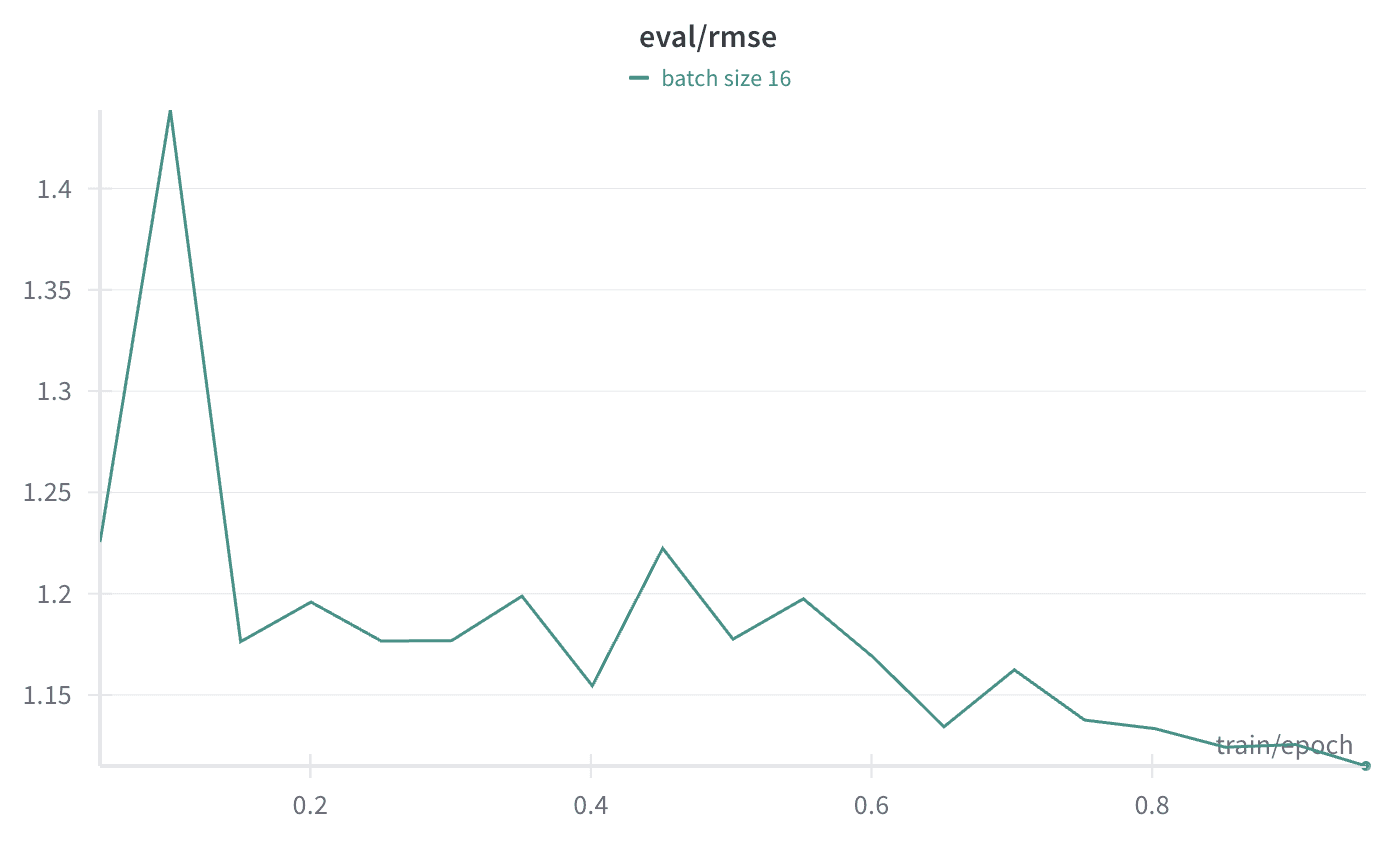
The model finishes with a root mean-square error (RMSE) of 1.11. Remember, we’re asking the model to predict log(score). To translate that back to its accuracy on the real score we reverse the log: e^1.11 ~= 3. This means that on average, our model’s predicted score is off by a factor of 3. Is that still good enough to be useful? We’ll see!
Running Inference
Let’s see what our model thinks of all the HN stories! I used this code to run our model against the entire corpus of HN stories. I found that using the Transformers library, along with the Liger Kernels we used for training gave adequate performance without resorting to an inference-focused library like sglang. I again ran this on an H100 on RunPod, and it only took 15 minutes to process all 140K stories in the corpus.
Ok, let’s limit to our test set and see how well our model does at predicting scores! Here’s a heatmap comparing the model’s predicted log(Score) on the Y-axis to the real log(Score) on the X-axis:

Interesting! The correlation is actually not bad (0.53), but our model is very consistently over-estimating the score at the low end, and underestimating it at the high end. This is surprising; some variation on any given data point is expected, but such a consistent mis-estimation trend isn’t what we’d expect.
What causes this? I don’t know for sure, but I suspect this is an artifact of the randomness in getting to the HN front page. You can think of a post’s predicted score as
predicted_score = (probability_of_hitting_front_page * final_score_if_it_hits_front_page)
Even if the model gets extremely good at predicting final_score_if_it_hits_front_page, there’s still the inherent randomness of probability_of_hitting_front_page that is fundamentally unpredictable. As a result, the model learns to “hedge its bets” by predicting a score somewhere between 0 and the “true” predicted score if this story were to hit the front page.
So, how good are the stories it picks? Let’s take a look!
Let’s see the stories!
How well does the model do on identifying great HN stories? Here are the top 10 stories it predicts as most successful, with both the predicted and actual score(3).
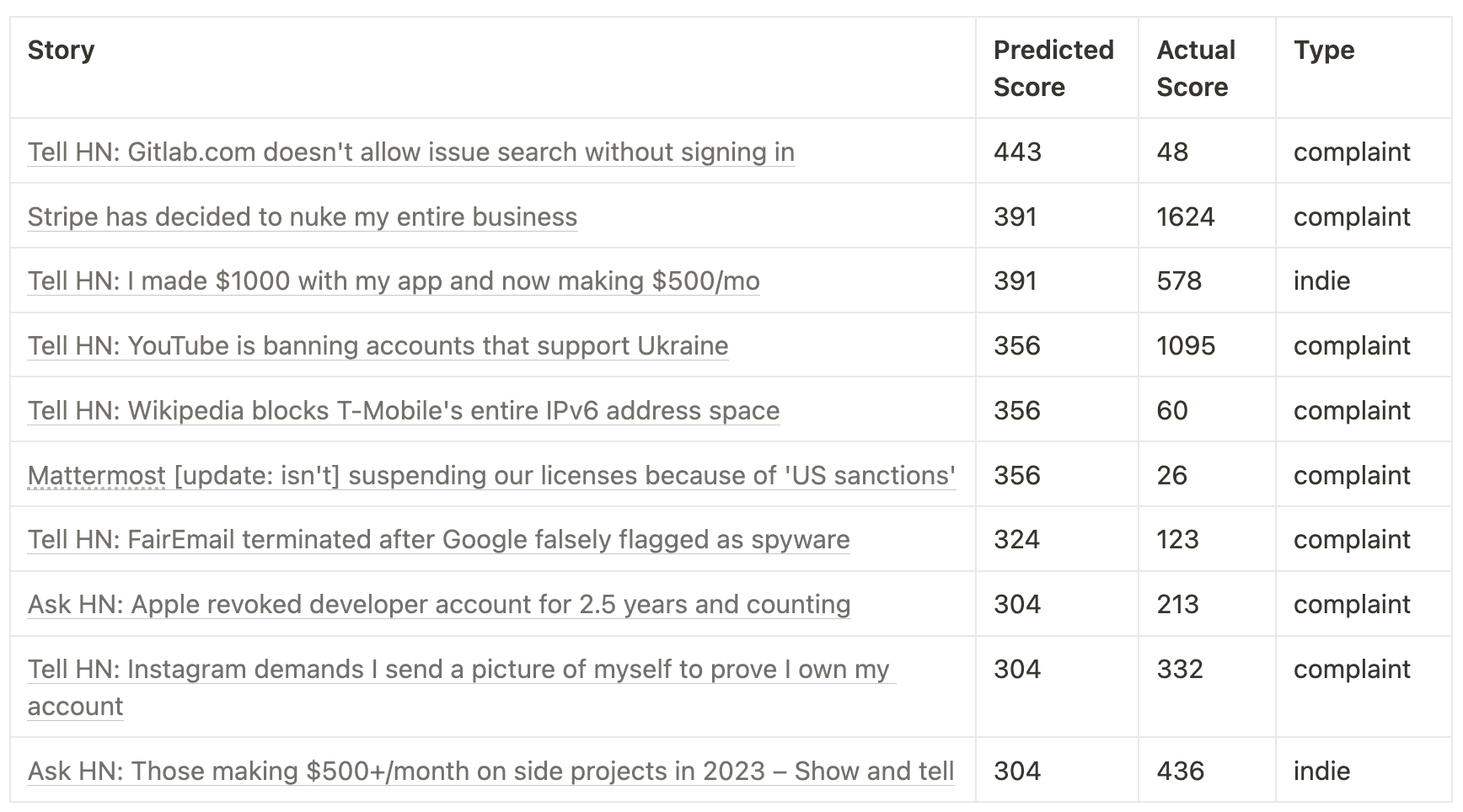
Ok, those seem… interesting. It seems like the model has correctly identified that service complaints (8/10) and people talking about indie apps making money (2/10) very reliably make it to the front page, which all 10 apparently did!
We can also look at the top stories that the model believes should be successful, but actually fell through the cracks. Here are the top-predicted-score stories with a real score of 1 (zero upvotes):
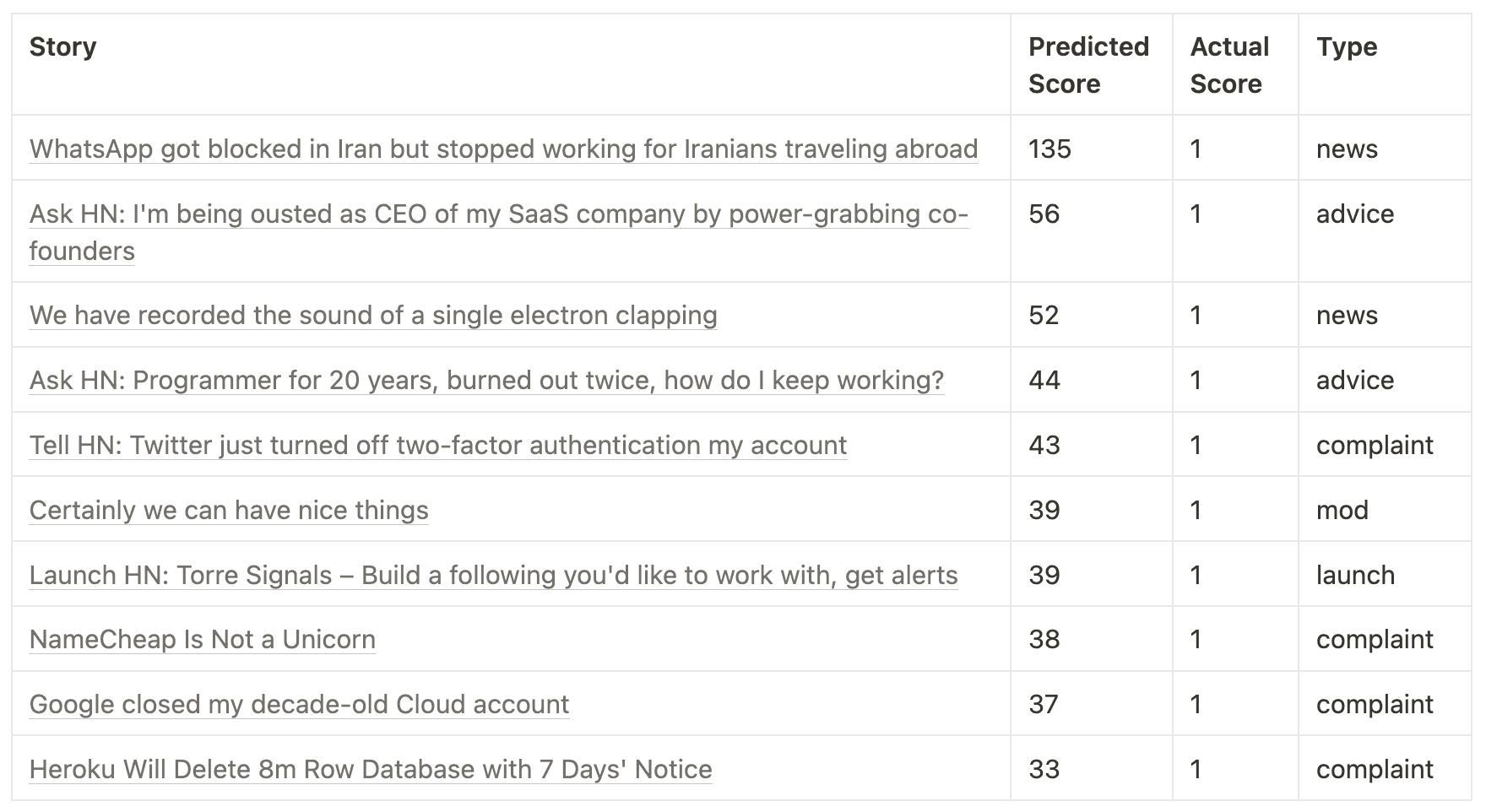
There are some nice gems on this list! Still a lot of complaints (4/10) but some more interesting content as well. There are some good diamonds in the rough there that probably should have sparked more discussion like dealing with Machiavellian co-founders, pushing through burn-out, and recording a signal from a single electron.
Part 2: Writing a Great HN Post
Our reward model helps us define what a good HN post looks like. Is there anything else we can do with it? Yes! A fundamental property of machine learning is that if something can be measured, it can be optimized! So now that we can measure post quality, can we actually improve it? RLHF gives us a powerful set of techniques to do so, which we’ll cover in the next post in the series. 
And as a final plug: if you have an AI-powered app deployed in production and a possible source of feedback, please contact me at kyle@openpipe.ai. We are working closely with a number of design partners on improving our RLHF stack and would love to help you get better quality on your tasks!
Footnotes
-
This query took 17 seconds to load the dataset into RAM and then aggregating by type was almost instant. It is absolutely incredible to me that I can load every HN post and comment ever into RAM in a few seconds on my (admittedly beefy) dev laptop, and analyze them at will. What an age of abundance!
-
We actually do slightly modify the architecture of the model to make it work more naturally as a reward model. Instead of the model’s final layer having a separate output for every possible token, we just have a single output that we train to predict the reward signal.
-
Since 80% of our stories were in the training set we have to worry about memorization here. Maybe the model is just remembering that these specific stories got a high score? After looking at the data a bit more closely though I don’t think that’s the case. only 7/10 of these stories were in the training set, less than the 80% proportion that were in the training set overall. So the model doesn’t seem to have the bias towards high-scoring stories in the training set you’d expect if it were just memorizing the distribution.

