
LeanDojo: Theorem Proving in Lean using Language Models
LLMs as Copilots for Theorem Proving
We introduce Lean Copilot for LLMs to act as copilots in Lean for proof automation, e.g., suggesting tactics/premises and searching for proofs. Users can use our model or bring their own models that run either locally (w/ or w/o GPUs) or on the cloud.
Overview of LeanDojo
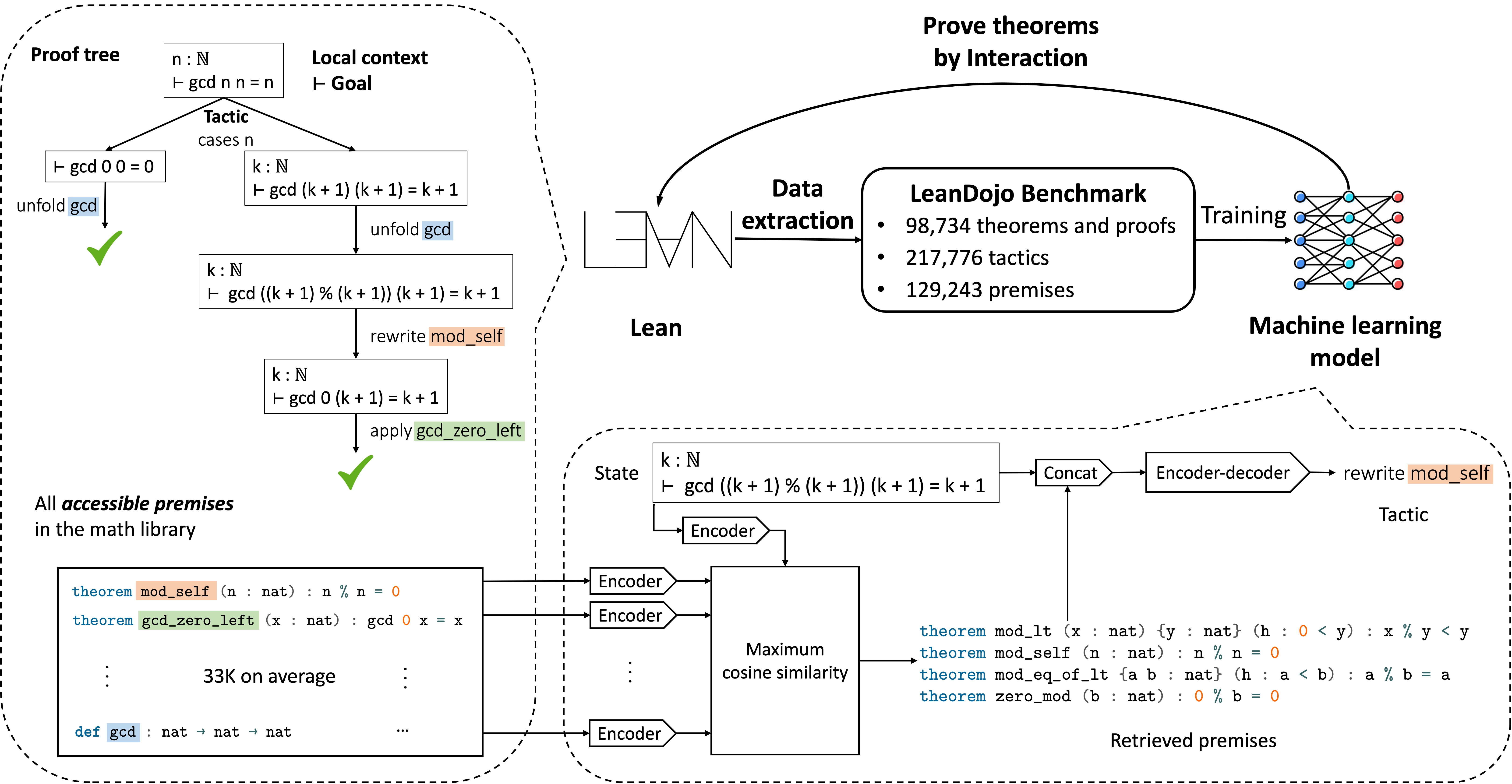
Top right: LeanDojo extracts proofs in Lean into datasets for training machine learning models. It also enables the trained model to prove theorems by interacting with Lean’s proof environment.
Top left: The proof tree of a Lean theorem (forall n in mathbb{N},~texttt{gcd n n = n}), where (texttt{gcd}) is the greatest common divisor. When proving the theorem, we start from the original theorem as the initial state (the root) and repeatedly apply tactics (the edges) to decompose states into simpler sub-states, until all states are solved (the leaf nodes). Tactics may rely on premises such as (texttt{mod_self}) and (texttt{gcd_zero_left}) defined in a large math library. E.g., (texttt{mod_self}) is an existing theorem (forall n in mathbb{N},~texttt{n % n = 0}) used in the proof to simplify the goal.
Bottom: Our ReProver model. Given a state, it retrieves premises from the math library, which are concatenated with the state and fed into an encoder-decoder Transformer to generate the next tactic.
Benchmarks
 LeanDojo Benchmark: 98,734 theorems/proofs, 217,776 tactics, and 130,262 premises from mathlib.
LeanDojo Benchmark: 98,734 theorems/proofs, 217,776 tactics, and 130,262 premises from mathlib. LeanDojo Benchmark 4: 122,517 theorems/proofs, 259,580 tactics, and 167,779 premises from mathlib4.
LeanDojo Benchmark 4: 122,517 theorems/proofs, 259,580 tactics, and 167,779 premises from mathlib4.
LeanDojo can extract data from any GitHub repos in Lean (supporting both Lean 3 and Lean 4). The data contains rich information not directly visible in the raw Lean code, including file dependencies, abstract syntax trees (ASTs), proof states, tactics, and premises.
Key feature 1: Premise information: LeanDojo Benchmark contains fine-grained annotations of premises (where they are used in proofs and where they are defined in the library), providing valuable data for premise selection—a key bottleneck in theorem proving.
Key feature 2: Challenging data split: Splitting theorems randomly into training/testing leads to overestimated performance. LLMs can prove seemingly difficult theorems simply by memorizing the proofs of similar theorems during training. We mitigate this issue by designing challenging data split requiring the model to generalize to theorems relying on novel premises that are never used in training.
Interacting with Lean
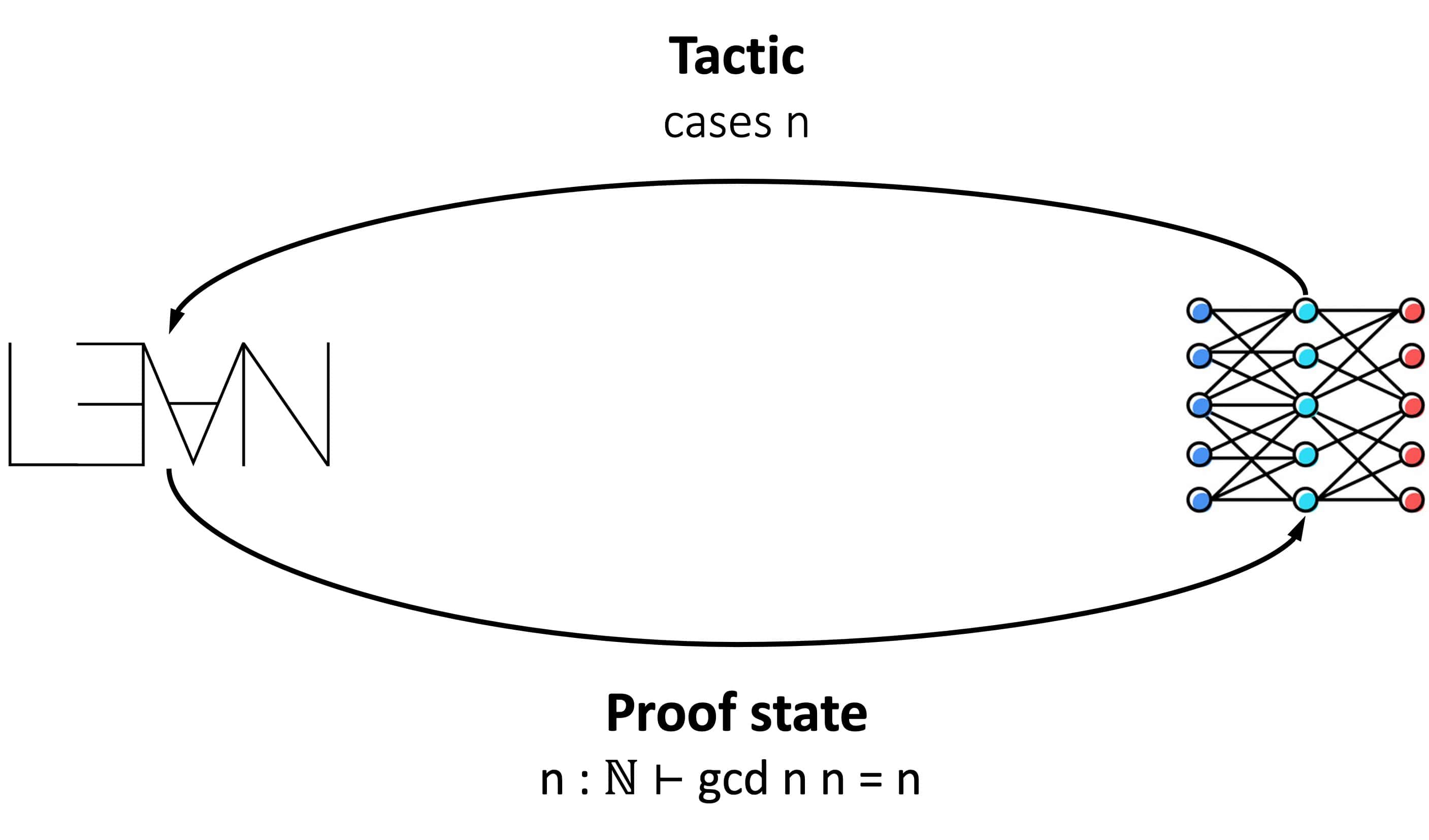
LeanDojo turns Lean into a gym-like environment, in which the prover can observe the proof state, run tactics to change the state, and receive feedback on errors or on proof completion. This environment is indispensable for evaluating/deploying the prover or training it through RL.
Experiments

We use LeanDojo Benchmark to train and evaluate ReProver. During testing, the tactic generator is combined with best-first search to search for complete proofs. The table shows the percentage of theorem proved within 10 minutes. The (texttt{novel_premises}) spilt is much more challenging than the (texttt{random}) split. On both data splits, ReProver outperforms Lean’s built-in proof automation tactic (tidy), a baseline that generates tactics directly without retrieval, and another baseline using GPT-4 to generate tactics in a zero-shot manner.
Discovering New Proofs and Uncovering Formalization Bugs
We evaluate ReProver on theorems in miniF2F and ProofNet. It discovers 33 proofs in miniF2F and 39 proofs in ProofNet of theorems that did not have existing proofs in Lean. Our proofs have helped ProofNet uncover multiple bugs in the formalization of theorem statements.
ChatGPT for Theorem Proving
We build a LeanDojo ChatGPT plugin that enables ChatGPT to prove theorems by interacting with Lean. Compared to specialized LLMs finetuned for theorem proving (e.g., ReProver), ChatGPT can interleave informal mathematics with formal proof steps, similar to how humans interact with proof assistants. It can explain error messages from Lean and is more steerable (by prompt engineering) than specialized provers. However, it struggles to find correct proofs in most cases, due to weakness in search and planning.
Team
BibTeX
@inproceedings{yang2023leandojo,
title={{LeanDojo}: Theorem Proving with Retrieval-Augmented Language Models},
author={Yang, Kaiyu and Swope, Aidan and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima},
booktitle={Neural Information Processing Systems (NeurIPS)},
year={2023}
}
@article{song2024towards,
title={Towards Large Language Models as Copilots for Theorem Proving in {Lean}},
author={Peiyang Song and Kaiyu Yang and Anima Anandkumar},
year={2024},
journal = {arXiv preprint arXiv: Arxiv-2404.12534}
}

